
I must add the vendor was quite respectful of both points faculty brought up. They said they were unaware plural pronouns were now acceptable as gender neutral single pronouns and would change their manual.
Tag: AdventuresInBadScience
So now students may or may not get into #teacheredchat programs or may not get a license because of their scores on assessments built on #BadScience. What happened to respecting and trusting #highered faculty? The assessments are just as bad
what they want to measure, “Does this person have what it takes to teach?” We just don’t know how to measure it. Instead of empowering faculty we developed a data fetish to appease @CAEPupdates They want pretty charts, good data be damned
Just because we SHOULD do something doesn’t mean we CAN do something. Read the literature. NO ONE HAS ANY IDEA HOW TO MEASURE DISPOSITIONS OF TEACHING AT SCALE. Saying anything else is a lie. Possibly worse than #BadScience #HigherEd
told by powers to be at university of assessment, ” @CaepUpdates says the assessment is reliable and valid and they like it, so it is reliable” That is not how science works. That is how #BadScience works #HigherEd
Methods section of the “testing manual” was so light on detail you wouldn’t be able to reproduce the study…and I still don’t know what a Pearson Correlation of .26 is “considered high” because they were measuring “content validity” means
Yesterday when I asked to see testing manual. Something you should ask of every test vendor I found this chart. 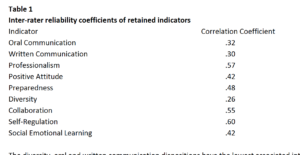
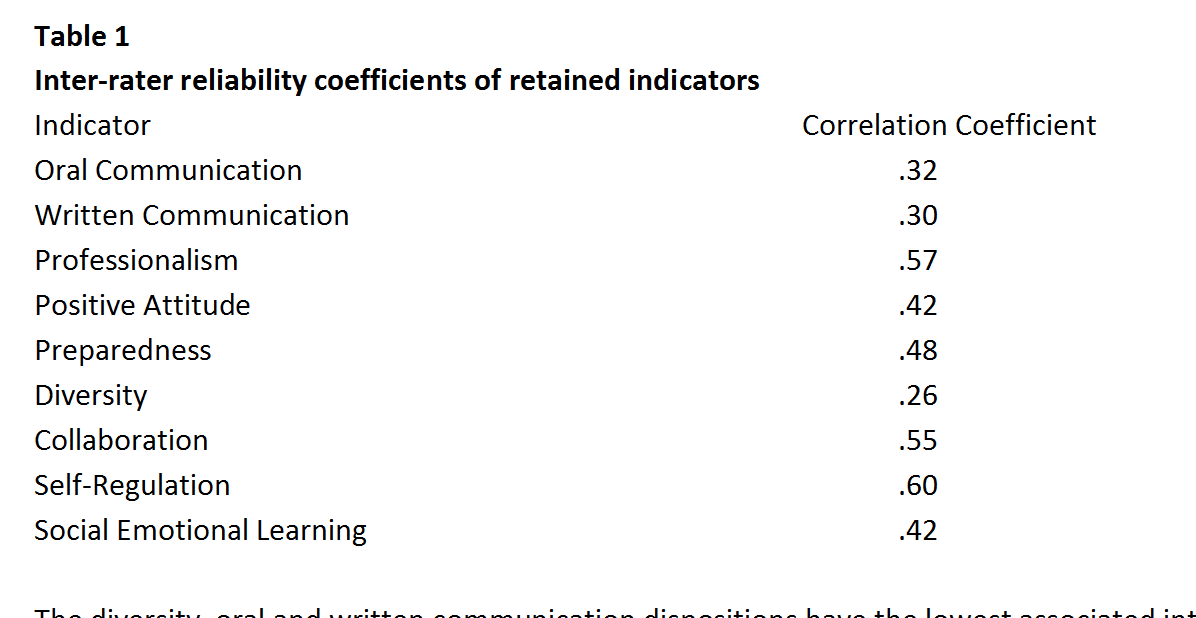
We were told don’t worry about low coefficients this is content validity so those are high. What does that even mean?
Do not let @caepupdates or any test vendor tell you a rubric is reliable. Definition of #BadScience. Rubrics aren’t reliable. Reliability needs to be established at each administration, with each group of raters, with each batch.
Do we know no history? I am not walking into a classroom of minority students and telling a teacher of color they do not speak with proper grammar. The embedded racism in such a task is just so wrong.
oral grammar even considered a disposition? I don’t think word disposition means what @caepupdates and the assessment companies that fund @caepupdates means what they think it means. Why are there single item scales?